Windsurf

VS Code
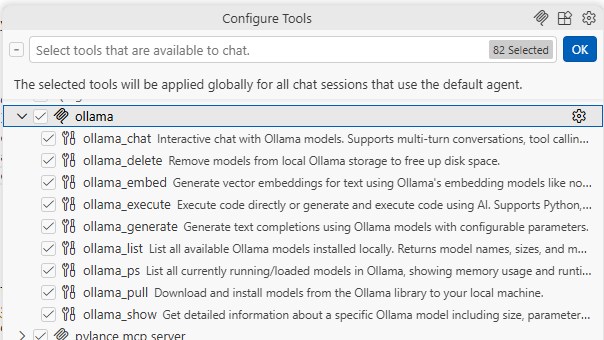
Multi-turn conversations with any local Ollama model. Supports tool calling, structured outputs, and image inputs.
Generate completions with configurable parameters — temperature, top_p, top_k, repeat penalty, and stop sequences.
List, inspect, pull, and delete models directly from your AI assistant. No terminal needed.
Generate embeddings for text using models like nomic-embed-text. Power your RAG pipelines and semantic search.
Zero-config tool discovery — drop a new tool file in the tools directory and it's automatically registered.
Run local models and Ollama Cloud models seamlessly from one server. Use the right model for the job.
Works out of the box with Windsurf, VS Code, and any MCP-compatible client. Just add the server config.
Built with async/await, Pydantic models, and Poetry. No Node.js required — pure Python, minimal dependencies.